

Процесс создания своего парсера может показаться достаточно сложным и запутанным для новичков, особенно, если нужно писать программу с чистого листа. Ситуацию меняет наличие готовых профильных библиотек, таких как Beautiful Soup (написана на Python, а этот язык программирования сам по себе идеален для новичков).
И да, пусть название библиотеки не вводит вас в заблуждение, мы не будем рассказывать «как готовить прекрасный суп». Никакого отношения к готовке этот материал не имеет. Хотя… это же тоже инструкция, которую можно пройти по шагам! Поехали.
Что такое Beautiful Soup?

Beautiful Soup – это библиотека для Python, предназначенная для ускорения написания собственных утилит парсинга web-страниц. Она преобразует HTML-код в аналог индексированного словаря.
Разработчики библиотеки ставили себе задачу облегчить жизнь многим программистам, ведь задачи парсинга возникают в различных технических проектах. А это не только сбор информации о конкурентах или автоматизация мультиаккаунтов.
К ключевым фишкам Beautiful Soup можно отнести:
- Предоставление простых методов и идиом для навигации, поиска и изменения дерева синтаксического анализа.
- Быстрое преобразование документов в Unicode и UTF-8.
- Работа в паре с другими популярными синтаксическими анализаторами, такими как lxml и html5lib (их можно переключать при вызове в коде через передачу специальных параметров).
А ещё:
- Несмотря на первый релиз в далёком 2004 году, Beautiful Soup активно развивается и обновляется по сей день.
- Код распространяется в открытом виде по лицензии MIT, поэтому библиотеку можно включить в состав любого приложения на Python (даже если оно коммерческое).
- Создание комплексных парсеров с её помощью может занимать минуты (против нескольких часов или дней в исполнении профессиональных программистов).
- От пользователей требуется минимум своего кода.
- Поддерживается извлечение данных не только из HTML, но и из XML-документов.
- При желании Beautiful Soup может интегрироваться с headless-браузерами (за счёт передачи результирующего HTML-кода из них на анализ в bs4).
Библиотеку написал и продолжает поддерживать Леонард Ричардсон, python-разработчик, эксперт проектирования RESTful API, по совместительству писатель-фантаст.
Если описать кратко принцип работы библиотеки, то она преобразует сложный HTML-документ в дерево объектов Python. Их 4 типа: Tag, NavigableString, BeautifulSoup и Comment. К тегам можно применять различные методы и атрибуты, что, в конечном итоге и ускоряет обратку документа.
Например, вы можете делать быстрые выборки по типу «все ссылки страницы», «все цитаты» и т.п. А можно перемещаться по горизонтальным (равным друг другу по уровню) элементам: первый, второй, третий и т.п., последний.
Основные этапы веб-скрапинга с помощью Beautiful Soup

Чтобы начать парсить сайты, вам нужно подготовить программную среду, то есть установить Python, затем саму библиотеку, а также ряд других компонентов, и только потом переходить к практической реализации – к написанию скриптов.
Давайте разобьём всё на шаги и пройдём по каждому подробнее.
1. Предварительные требования и настройка среды
Установите Python. Для этого посетите официальную страницу загрузки и скачайте актуальную версию Python. На момент написания статьи стабильной веткой Питона является 3.13. На всякий случай, для понимания: библиотека Beautiful Soup может работать в том числе в старых версиях Python – вторая ветка (не ниже версии 2.17) и третья (начиная с 3.2 и выше).
Установка Python возможна на ПК с Windows, MacOS и Linux. Во многих популярных дистрибутивах Python уже предустановлен. При желании Python можно даже установить и использовать на мобильных гаджетах: iOS, Android.
Важно! При установке Python в Windows обязательно отметьте галочку «Add python.exe to PATH». Так вы автоматически добавите исполняемый файл к системным переменным средам. В противном случае это нужно будет сделать вручную, чтобы исполняемую среду можно было вызывать одной командой и не обращаться каждый раз к полному имени файла (C:\Program Files\Python313\python.exe или C:\Users\ВАШ_ЛОГИН\AppData\Local\Programs\Python\Python313\python.exe, в зависимости от типа установки).
Актуальная версия Beautiful Soup – 4.12. При желании вы можете скачать устаревшую третью версию, но учтите, что разработчики ею больше не занимаются и не актуализируют.
Так как Beautiful Soup распространяется через официальный репозиторий, то достаточно воспользоваться командой в консоли Python:
pip install beautifulsoup4Если команда pip выводит ошибку, то скорее всего её тоже нужно добавить в PATH. Если вы этого не сделали, то введите в терминале:
python -m pip install beautifulsoup4Если вы используете менеджер пакетов easy_install, то используйте команду:
easy_install beautifulsoup4В Linux-дистрибутивах Ubuntu/Debian Beautiful Soup можно установить как штатный пакет программ:
apt-get install python3-bs4 (если нужна версия для Python 3+)apt-get install python-bs4 (если нужна версия для Python 2)Более опытные пользователи могут скачать исходный код и установить библиотеку вручную.
Если вам важна поддержка разных версий парсеров, можно дополнительно установить lxml и html5lib:
pip install lxmlpip install html5libЕсли вы хотите взаимодействовать с внешними серверами, вам придётся отправлять и получать http-запросы. Чтобы упростить процесс формирования http-заголовков, установите библиотеку requests:
pip install requestsСледите за тем, чтобы все исполняемые файлы и скрипты Python были в одном месте, например, часть библиотек при установке может сохраняться в C:\Users\ВАШ_ЛОГИН\AppData\Roaming\Python\Python313\Scripts. Ну или проверяйте регулярно правильность путей в системных переменных (указанных в PATH).
Для тестовых парсеров можно работать с локальными HTML-документами.
Резидентные прокси
Лучшие прокси-серверы для доступа к ценным данным со всего мира.
2. Понимание основ структуры HTML
HTML – это язык гипертекстовой разметки. По факту это набор специальных тегов и их параметров, которые предназначены для чтения браузером. Браузер на основе HTML-тегов отрисовывает итоговую версию страницы.
Простейший пример HTML-страницы:
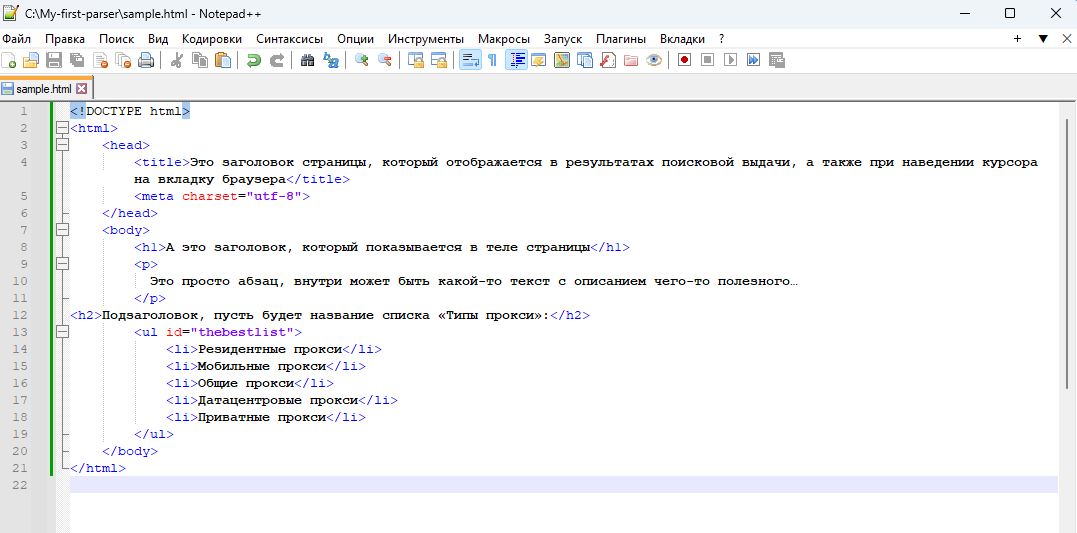
<!DOCTYPE html><html><head><title>Это заголовок страницы, который отображается в результатах поисковой выдачи, а также при наведении курсора на вкладку браузера</title><meta charset="utf-8"></head><body><h1>А это заголовок, который показывается в теле страницы</h1><p>
Это просто абзац, внутри может быть какой-то текст с описанием чего-то полезного…
</p><h2>Подзаголовок, пусть будет название списка «Типы прокси»:</h2><ul id="thebestlist"><li>Резидентные прокси</li><li>Мобильные прокси</li><li>Общие прокси</li><li>Датацентровые прокси</li><li>Приватные прокси</li></ul></body></html>
Можете открыть любой текстовый редактор, скопировать в него весь код, приведённый выше, и сохранить в виде текстового файла в любом каталоге на компьютере. Обязательно смените расширение файла с .txt на .html.
Если открыть этот файл в браузере, то вы увидите подзаголовок и список разных типов прокси. Никакого лишнего кода не будет.
Теги <head>, <body>, <p>, <ul>, <li> и прочие нужны только для браузера. Большинство тегов имеет открывающий и закрывающий элемент (<li>Содержимое тега</li>), закрывающий тег содержит косую черту. Но иногда тег может содержать только один элемент, пример: <img src="images/some-img.png" alt="Альтернативный текст">.
Внутри тегов могут использоваться стили и другие атрибуты. Пример: <a href="https://site.name/index.html">Это ссылка</a>. Здесь с помощью href передаётся URL-адрес страницы.
По аналогии работают стили, классы и идентификаторы:
<div class="container large-box"><!-- Какой-то блок. Кстати, так в HTML записываются комментарии, они не показываются пользователям в браузере, но видны в коде --></div>
У нашего div-блока сразу два CSS-класса – «container» и «large-box». Обработчику CSS можно описать параметры декорирования блока с помощью специального синтаксиса.
Пример:
<style>.container {background-color: yellow;font-size: 18px;}</style>
Стили можно описать прямо в HTML-коде, заключив между тегами <style>…</style>, а можно подключить в виде ссылки на файл (например, <link rel="stylesheet" type="text/css" href="https://site.name/styles.css">). Реже стили описываются прямо внутри тега (инлайн).
Если вы хотите погрузиться глубже в HTML, CSS и JavaScript, то можно изучить официальные спецификации или пройти профильные курсы.
Наша сегодняшняя задача – дать понять, как работает парсер. Поэтому остановимся на том коде, который мы привели выше.
3. Выполнение HTTP-запросов и парсинг HTML с помощью Beautiful Soup
Создайте папку для своих Python-скриптов. Пусть это будет «C:\My-first-parser».
Скопируйте содержимое HTML, которое мы привели во втором пункте, и сохраните в виде файла sample.html в папке с python-скриптами: C:\My-first-parser\sample.html.
В том же каталоге создайте свой первый скрипт:
- Переместитесь в каталог C:\My-first-parser.
- Создайте текстовый файл. Пусть это будет true-code.txt.
- Смените расширение с .txt на .py. Должно получиться true-code.py.
- Откройте файл в текстовом редакторе и наполните его содержимым (будьте внимательны к пробелам в начале строк, Python их учитывает):
from bs4 import BeautifulSoupwith open('sample.html', 'r') as file:content = file.read()soup = BeautifulSoup(content, "html.parser")for child in soup.descendants:if child.name:print(child.name)
- Сохраните файл.
- Запустите свой первый python-парсер (наберите в консоли): python C:\My-first-parser\true-code.py
Должно вывестись что-то похожее:

Примерно так видит ваш документ библиотека Beautiful Soup. Она проиндексировала все HTML-элементы и создала на их основе готовый массив. Зная синтаксис команд Beautiful Soup, очень легко делать выборку по такому массиву.
В примере мы считывали готовый файл. А вот так можно обратиться к реальному сайту:
import requestsfrom bs4 import BeautifulSoupresponse = requests.get("https://news.ycombinator.com/")if response.status_code == 200:html_content = response.contentprint(html_content)else:print(response)soup = BeautifulSoup(html_content, "html.parser")for child in soup.descendants:if child.name:print(child.name)
После исполнения такого скрипта в консоли сначала будет выведен весь HTML-код страницы, а затем последовательно названия всех HTML-элементов, уже после обработки библиотекой BeautifulSoup.
Давайте разберём, что же сделала наша программа:
import requestsfrom bs4 import BeautifulSoupЗдесь мы импортируем библиотеки requests и bs4 (BeautifulSoup).
response = requests.get("https://news.ycombinator.com/")Обращаемся к конкретной странице, «https://news.ycombinator.com/». Метод requests.get() заимствован из библиотеки requests. Он возвращает ответ севера.
Далее мы анализируем ответ сервера:
if response.status_code == 200:Если код ответа 200 (это значит, что сервер работает и страница, к которой вы обращаетесь, существует), тогда мы извлекаем HTML-содержимое и наполняем переменную html_content.
html_content = response.contentЧтобы убедиться, что переменная наполнена, выводим её в консоль:
print(html_content)Но ведь мы не использовали Beautiful Soup! Создаём переменную soup и обращаемся к методу BeautifulSoup(). Передаём ему наш HTML-контент и просим распарсить.
soup = BeautifulSoup(html_content, "html.parser")Атрибут .descendants перебирает все дочерние теги внутри корневого тега <html> и получает массив. Нам остаётся только последовательно вывести имена найденных тегов, это делается в цикле for:
for child in soup.descendants:if child.name:print(child.name)Глобальное покрытие
5 континентов, Никаких ограничений
Получите доступ к прокси-сети с 200+ локациями и 10+ миллионами IP-адресов.
4. Навигация и извлечение данных
Усложним задачу: выведем заголовок страницы, посчитаем все ссылки и спарсим только текст.
Скопируете код ниже и замените содержимое файла C:\My-first-parser\true-code.py.
import requestsfrom bs4 import BeautifulSoup# Запрашиваем HTML-содержимое страницы и передаём его в переменную html_content, если код ответа сервера отличается от 200, то выводим только ответresponse = requests.get("https://news.ycombinator.com/")if response.status_code == 200:html_content = response.contentelse:print(response)# Передаём HTML-содержимое на анализ в библиотеку BeautifulSoupsoup = BeautifulSoup(html_content, "html.parser")# Выводим весь тег titleprint(soup.title)# То же самое, но уже без тегов вокруг, только содержимоеprint(soup.title.string)# Ищем все ссылки, найденные на странице (по тегу <a>) и считаем их количествоall_links = len(soup.find_all("a"))print(f"На странице найдено {all_links} ссылок")# Весь текст со страницыprint(soup.get_text())
На выходе должно получиться что-то похожее:

Так как сайт может не работать или его содержимое может измениться, вернёмся к нашему HTML-файлу (чтобы результат был гарантированным).
Попробуем найти в нём список (тег ul) с идентификатором «thebestlist», а затем выведем все элементы списка (они имеют тег li).
Код скрипта:
from bs4 import BeautifulSoup# Открываем наш HTML-файл и передаём содержимое в переменную htmlcontentwith open('sample.html', 'r') as file:htmlcontent = file.read()soup = BeautifulSoup(htmlcontent, "html.parser")# Ищем тег ul с атрибутом id=thebestlist. Обратите внимание, если элементов будет несколько, будет выведен только первый. Так как у нас список только один, он будет "напечатан" весь, вместе с дочерними элементамиprint(soup.find('ul', attrs={'id': 'thebestlist'}))# А тут в цикле перебираем все найденные теги li (то есть элементы списка)for tag in soup.find_all('li'):print(tag.text)
А вот так выглядит вывод консоли (если вдруг, вы работаете в Windows с кириллицей, то проследите за тем, чтобы кодировка HTML-файла соответствовала штатной кодировке ОС, то есть ANSI):

Поздравляем, ваш первый парсер работает!
Можно попробовать и что-то посложнее:
print(soup.select_one('body ul li:nth-of-type(3)'))
Команда выведет в консоли третий элемент из списка.
print(soup.select_one('ul:nth-child(1) > li:nth-child(2)'))
А эта выведет второй элемент li в первом найденном списке ul.
Ниже пример кода для обхода нескольких страниц. Если попытки запроса завершаются неудачно, парсер будет пытаться обращаться к странице несколько раз. Результат будет выгружаться в JSON файл «hn_articles.json» в папке пользователя (C:\Users\ВАШ_USER):
import requestsfrom bs4 import BeautifulSoupimport timeimport json# Инициируем переменныеis_scraping = True # Статус парсера, истина = работаетcurrent_page = 1 # Текущая страница, будет наращиваться по +1 за итерациюscraped_data = [] # Массив для хранения данныхmax_retries = 3 # Максимальное количество попыток парсингаprint("Парсинг новостей с Hacker News запущен...")# Повторяем переключение на новые страницы, пока парсинг не завершитсяwhile is_scraping:try:# Делаем запрос к страницеresponse = requests.get(f"https://news.ycombinator.com/?p={current_page}") #начинаем с 1 и далее прибавляем индекс по одномуhtml_content = response.contentprint(f"Парсинг страницы {current_page}: {response.url}")# Используем библиотеку BeautifulSoup для разбора HTML содержимогоsoup = BeautifulSoup(html_content, "html.parser")# Ищем все элементы с классом "athing"articles = soup.find_all(class_="athing")# Если содержимое существует, то...if articles:# Извлекаем данные со страницыfor article in articles:article_data = {"URL": article.find(class_="titleline").find("a").get("href"), # Находим элементы с классом "titleline", но забираем только атрибуты href, то есть ссылки"Title": article.find(class_="titleline").getText(), # Находим элементы с классом "titleline", но извлекаем текст"Rank": article.find(class_="rank").getText().replace(".", ""), # Находим элементы с классом "rank", извлекаем текст и заменяем точки на пробелы}# Добавляем новые данные в конец списка функцией appendscraped_data.append(article_data)print(f"Данные со страницы {current_page} извлечены успешно, найдено {len(articles)} статей.")# Провевяем наличие ссылки на следующую страницуnext_page_link = soup.find(class_="morelink") # Проверка делается по классу "morelink"# Если ссылка есть, то увеличиваем счётчик страниц, чтобы изменить ссылку для парсинга на следующую итерациюif next_page_link:current_page += 1# Если ссылки нет, то ставим статус парсинга "ложь"else:is_scraping = Falseprint(f"Парсинг завершен! Обработали: {current_page} страниц")print(f"Найдено новостей: {len(scraped_data)}")# Сохраняем данные в JSON файл, кодировку cp1251 выбрали намеренно для Windows, если у вас Linux, измените на utf-8with open("hn_articles.json", "w", encoding="cp1251") as jsonfile:json.dump(scraped_data, jsonfile, indent=4)except requests.exceptions.RequestException as e:print(f"Ошибка парсинга страницы {current_page}: {e}")# Задаём логику повторных попыток и задержек между запросамиfor attempt in range(1, max_retries + 1):print(f"Повторный запрос для страницы {current_page} (attempt {attempt}/{max_retries})...")time.sleep(2) # Измените задержку, если нужноtry:response = requests.get(f"https://news.ycombinator.com/?p={current_page}")break # Успешный запрос, продолжаем парсингexcept requests.exceptions.RequestException:pass # Продолжаем попытки, пока не достигнем лимита попытокelse:print(f"Сдались после {max_retries} попыток парсинга страницы {current_page}")# Добавляем задержку между запросамиtime.sleep(2)
Продвинутые методики работы с Beautiful Soup

Самая сложная задача – парсинг динамических сайтов. Такие сайты не имеют конечной HTML-структуры, точнее содержат только её часть, в которой указываются ссылки на JS-скрипты. Всё содержимое выстраивается непосредственно в браузере – после исполнения JavaScript-кода.
Beautiful Soup не умеет исполнять JS, поэтому вам понадобится полноценный браузер, чтобы сначала отрендерить страницу, а потом передать библиотеке результирующий HTML-код.
Чтобы максимально усложнить задачу, выгрузим массив найденных элементов в CSV-файл (в понятном многим табличном формате).
Вот так может выглядеть интеграция анализатора Beautiful Soup с headless-браузерами и экспортом в файл:
Сначала установим Selenium (вместо него могут использоваться и другие веб-драйверы, например, Playwright или Puppeteer, это инструменты для тестирования сайтов).
pip install selenium
Ну и для работы с CSV установим Pandas
pip install pandas
Итоговый скрипт будет выглядеть так:
# Подключаем библиотеки from selenium import webdriverfrom bs4 import BeautifulSoupimport pandas as panda# Открываем headless-браузер Хромdriver = webdriver.Chrome()# Передаём браузеру адрес страницы и получаем контентdriver.get("http://quotes.toscrape.com/js/")# Сохраняем результирующее содержимое в переменную js_contentjs_content = driver.page_source# Передаём содержимое на анализ внутри парсера BeautifulSoupsoup = BeautifulSoup(js_content, "html.parser")# Ищем все теги span с классом text, наполним ими массив quotesquotes = soup.find_all("span", class_="text")# Передаём массив в библиотеку Pandas и пишем данные в файл quotes.csv, кодировка 'cp1251' нужна для нормального отображения кириллицы в Windowsdf = panda.DataFrame({'Цитаты': quotes})df.to_csv('quotes.csv', index=False, encoding='cp1251')# На всякий случай дублируем вывод массива в консолиprint(quotes)
Согласитесь, это уже больше похоже на профессиональный подход. При этом объём кода реально мизерный.
Осталось самое страшное – прокси!
Многие крупные сайты и веб-сервисы защищаются от ботов. Плюс, если вы хотите ускорить процесс сбора информации, нужно задействовать несколько параллельных потоков. Всё это невозможно без прокси.
Для парсинга используются разные типы прокси: серверные, мобильные и резидентные, прямые и с обратной связью, на базе http или socks-протокола.
Мы рекомендуем ротируемые http-прокси с мобильными или жилыми адресами. Они подключаются в коде один раз и могут ротироваться автоматически за счёт большого пула адресов провайдера услуги, как раз, как у Froxy.
Пример кода:
# Подключаем библиотеки from selenium import webdriverfrom selenium.webdriver.common.proxy import *from selenium.webdriver.chrome.options import Optionsfrom bs4 import BeautifulSoup# Сюда вписываем ваши параметры проксиmyProxy = "188.114.98.233:80"proxy = Proxy({'proxyType': ProxyType.MANUAL,'httpProxy': myProxy,'sslProxy': myProxy,'noProxy': ''})# Устанавливаем параметры запуска службы web-драйвера для headless-браузера с использованием прокси, опций может быть больше, например, здесь же можно установить свой user-агент и т.п.options = Options()options.proxy = proxy# Запускаем веб-драйвер Chrome с нашими опциямиdriver = webdriver.Chrome(options=options)# Передаём браузеру целевую страницуdriver.get("https://httpbin.io/ip")# Сохраняем результирующее содержимое в переменную contentcontent = driver.page_source# Передаём содержимое на анализ внутри парсера BeautifulSoupsoup = BeautifulSoup(content, "html.parser")# Ищем содержимое тега <pre>yourip = soup.find("pre")# Выводим IPprint(yourip.text)# Освобождаем ресурсы и закрываем экземпляр браузераdriver.quit()
Если соединение через прокси будет успешным, то вы увидите его IP-адрес в формате:
{"origin": "188.114.98.233:80"}
Это только часть «сложного» функционала. По мере совершенствования навыков программирования можно задуматься о следующих вещах:
- Обработка пагинации и подгрузки динамического контента на одной странице.
- Поддержка экспорта в JSON и XML.
- Подмена и ротация user-агента, а также других HTTP-заголовков, которые отдают браузеры. Эмуляция полноценных цифровых отпечатков (например, вместо headless-браузеров можно начать использовать антидетект-браузеры, у них тоже есть API, но управлять большим количеством пользовательских профилей здесь гораздо удобнее).
- Многопоточность и управление задержками. Слишком частые автоматические запросы или запросы с равными промежутками времени быстро вычленяются и легко блокируются, затрудняя парсинг.
Выводы и рекомендации

Библиотека Beautiful Soup реально упрощает обработку HTML-кода. Да, из коробки в ней нет поддержки прокси или интеграций с headless-браузерами. Но всё это легко добавить за счёт других библиотек и скриптов.
Основная фишка библиотеки –принимать на вход ответ сервера (с произвольным HTML-кодом) и преобразовывать его в многомерный массив элементов. Зная синтаксис Beautiful Soup, можно быстро находить нужные вам теги и выводить их содержимое, сохранять в файлы или передавать другим потокам программы.
Чтобы парсер получился эффективным, нужно учесть массу технических мелочей: куки и цифровые отпечатки, задержки между запросами и многопоточность, работа через прокси.
Качественные прокси, которые легко подключаются к любым парсерам, можно найти у нас. Froxy – это 10+ млн. IP (серверные, резидентные и мобильные). Ротация возможна по времени или при каждом новом запросе (настраивается в личном кабинете), таргетинг до города и оператора связи.

