


Любые интернет-площадки с социальной составляющей интересны бизнесу. В первую очередь из-за своей аудитории, ведь на них можно прорекламировать товары и услуги. Но в социальных сетях, таких как TikTok, можно решать и другие задачи: собирать статистику, мониторить конкурентов, выявлять актуальные тенденции и т.п.
Как можно догадаться, этот материал о создании своего скрапера TikTok.
ТикТок – это оригинальный феномен. Соцсеть была запущена в Китае (на внутреннем рынке приложение называется «Доуинь») и ориентировалась на создание коротких видеороликов. Очень быстро TikTok из развлекательного ресурса превратился в поисковую систему, в которой можно найти короткие наглядные инструкции и мануалы на любую тему. Тут же можно изучить новости, мнения экспертов и многое другое.
Сейчас TikTok входит в пятёрку самых популярных сайтов с ежемесячной аудиторией, превышающей 1,58 млрд. пользователей (по данным за 2024 год). Что более интересно: аудитория здесь демонстрирует высокую вовлечённость, по статистике пользователи проводят за просмотром роликов около часа в день. Поколение Z вообще предпочитает TikTok для поисковых запросов (вместо Google).
Это ли не повод обратить особое внимание на данные, хранимые в TikTok?
Зачем парсить TikTok?
У каждого могут быть свои причины парсинга TikTok:
- Аналитики данных могут найти здесь новые тенденции и тренды, ключи для разгадки вопросов вовлечённости и поведения, а также информацию по эффективности того или иного контента.
- SMM-специалисты могут отслеживать показатели роста числа подписчиков для аккаунтов клиентов и их конкурентов, мониторить данные просмотров по опубликованным видео (чтобы понимать их эффективность), изучать вовлечённость и другие характеристики аудитории (для разработки более продуктивных стратегий продвижения).
- Интернет-маркетологи могут измерять показатели эффективности рекламных кампаний и выявлять предпочтения/триггеры целевой аудитории. Всё это нужно для правильной оптимизации расходов на рекламные кампании.
- Блогеры и авторы контента могут отслеживать данные по просмотрам своих видео, а также мониторить показатели конкурентов. На основе этого можно выявлять наиболее актуальные темы для будущих роликов и выстраивать более продуктивную стратегию продвижения, повышать вовлечённость и ещё больше наращивать свою аудиторию. Плюс можно существенно автоматизировать работу по взаимодействию с подписчиками.
- Бизнес и бренды могут отслеживать упоминания и узнаваемость, мониторить негатив (плохие отзывы или клевету) или просто общественное мнение, искать инфлюенсеров (новых представителей бренда), через которых в итоге можно увеличить свою узнаваемость и создать максимально положительный образ.
Естественно, задача любого парсера – повышение степени автоматизации. Те же самые действия можно производить и вручную, но они будут занимать значительно больше времени. Автоматический сбор информации за счёт парсинга делает вас быстрее и мобильнее. Правильно написанные скрипты снижают риски ошибок и дают информацию на выходе в нужном формате.
Ключевые моменты из условий использования TikTok относительно парсинга данных

Всегда, когда вы занимаетесь написанием своего парсера, не лишним будет изучить файл robots.txt (актуальная версия для TikTok) и правила использования/пользовательское соглашение (правила TikTok).
В файле robots.txt описываются разрешения и запреты на обход/индексирование определённых разделов сайта.
В случае с TikTok парсинг запрещён для таких разделов, как /inapp, /auth, /embed, /link, */directory/ (здесь обычно хранятся файлы), /search/video?, /search/user?q= и /shop/view/product/ (страницы конкретных товаров в магазинах пользователей).
С недавних пор платформа сделала открытый API для исследований (условия использования программного интерфейса TikTok для автоматических исследований). Но услуга доступна пока только для компаний из Европейской экономической зоны. В частности, по API можно собирать данные о:
- Профилях пользователей и их подписчиках, понравившихся и закреплённых видео, о репостах.
- Комментариях, подписях, субтитрах, отметках «Нравится» и числовых показателях просмотров к конкретным видео.
- Магазинах в TikTok (рейтинги, отзывы, цены и показатели продаж).
Документация по вызовам API TikTok.
При использовании API (TikTok Research Tools) устанавливаются индивидуальные квоты по числу запросов (пропускной способности), а также запрещается параллельное использование программ-парсеров. Компания-партнёр автоматически становится участником процесса защиты персональных данных пользователей (GDPR, CCPA и т.п.) со всеми вытекающими юридическими последствиями.
Заявка на создание исследовательского аккаунта может рассматриваться до 4 недель.
Если вам не подходят такие условия, логично написать свой TikTok-парсер и начать собирать данные так же, как это делают боты поисковых систем. Но тут стоит учесть, что официальные правила TikTok запрещают использование скриптов автоматизации, создание паразитной нагрузки (способной нарушить работу или качество сервиса), сбор персональных данных без официального разрешения владельцев площадки, а также создание фейковых учётных записей (с ложными/фальшивыми данными).
При всём этом доступ к контенту сайта возможен без авторизации. А значит, пользователей сложно идентифицировать и привлечь хоть к какой-то ответственности.
Но хватит теории, переходим к практической части.
Технические требования для парсера TikTok
Как парсить аккаунты пользователей в Instagram и TikTok? Технически всё просто. Все парсеры устроены примерно одинаково. Одна часть программы обходит страницы и получает их HTML-код, а вторая разбирает код на составляющие и вычленяет нужные данные. Они выгружаются в таблицу, в файл, базу данных или в другую программу.
Но есть и определённые требования, которые характерны для отдельных сайтов/web-сервисов. Для TikTok-парсера можно описать следующие моменты:
- Основной контент здесь – это видеоролики. Поэтому, если вы хотите изучать содержимое, то вам потребуются технологии компьютерного зрения или API специальных нейросетей, способных возвращать описание в ответ на ссылку.
- Если вам нужны только данные для анализа, то придётся изучать всё по косвенным признакам: длительность видео, количество просмотров, лайков, комментариев и т.п.
- Сайт TikTok динамический, это значит, что вместо HTML-разметки браузер получает набор JavaScript-скриптов. То есть классические библиотеки анализа HTML не помогут. Каждую страницу сайта нужно пропускать через браузер или через движок рендеринга JavaScript.
- TikTok активно борется с паразитным трафиком (не зря запрет на автоматизацию явно указан в правилах использования). Поэтому нужно заранее продумать механизмы «очеловечивания» парсера. Мало установить user-агент, нужно проверить также и остальные параметры цифрового отпечатка и подумать об использовании прокси.
Создание базового парсера TikTok

Начнём с подготовки среды разработки и установки нужных нам библиотек. В качестве языка программирования мы решили выбрать Python, так как на нём проще и быстрее всего писать комплексные парсеры. На всякий случай список лучших python-библиотек для парсинга.
Подготовка среды Python
Сначала нужно установить сам Python. Для этого нужно скачать дистрибутив с официального сайта Python. Актуальная версия языка – третьей ветки (на момент написания статьи это v3.13).
Во многих популярных Linux-дистрибутивах Python может быть уже установлен в системе. Если его нет, воспользуйтесь штатным менеджером пакетов.
При установке в среде Windows не забудьте добавить вызов основных команд в переменные среды.

Можно также добавить вызов менеджера пакетов pip, примерно, как на скрине ниже:

Плюс, желательно создать виртуальную среду в Python, чтобы файлы проекта не расползались по сторонним каталогам.
Введите команду:
python -m venv tiktok-scraper
После её исполнения для текущего пользователя будет создан каталог для вашей будущей программы. В случае с Windows это: C:\Users\ПОЛЬЗОВАТЕЛЬ\tiktok-scraper.
Теперь нужно активировать нашу виртуальную среду (введите команду в консоли):
tiktok-scraper\Scripts\activate.bat
Команда для PowerShell:
tiktok-scraper\Scripts\activate.ps1
Если консоль ругается на права запуска скриптов, то введите команду:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
И затем повторите процедуру активации окружения.
В Linux-системах команда активации будет другой:
source tiktok-scraper/bin/activate
Теперь все связанные библиотеки и скрипты будут храниться в каталоге виртуального окружения.
Устанавливаем библиотеки (по факту установится гораздо больше элементов, менеджер пакетов сам подтянет нужные зависимости):
pip install asyncio nodriver beautifulsoup4
Мы используем следующие библиотеки:
- Asyncio – инструмент для работы с асинхронными вызовами.
- Nodriver – драйвер для подключения к headless-браузеру, сразу умеющий маскировать следы своей работы, преемник библиотеки Undetected-Chromedriver. Официальная страница проекта на GitHub.
- Beautifulsoup4 – библиотека-анализитор HTML-кода. С ней выборка нужных элементов страницы будет выполняться максимально простыми и понятными командами. Подробный мануал о парсинге с помощью Beautiful Soup.
Проверка работы парсера TikTok
Создадим свой первый python-скрипт и запустим его. Скрипт должен будет открыть окно браузера в явном виде (без фонового исполнения), перейти на главную страницу TikTok, подождать 10 секунд и закрыться.
Для этого перейдите в каталог своего виртуального окружения (C:\Users\ВАШ_ПОЛЬЗОВАТЕЛЬ\tiktok-scraper) и создайте простой текстовый файл. Назовите его test.txt.
Теперь измените расширение .txt на .py.
Откройте файл в любом текстовом редакторе или в IDE-системе. Наполните его содержимым:
#Импортируем библиотеки для проекта, пока без beautifulsoup4import nodriver as headlesschromeimport asyncioasync def main():try:print("Запускаем браузер...")# Чтобы видеть результат работы браузера, запустим его явно. Для этого отключаем режим headlessbrowser = await headlesschrome.start(headless=False)# Передаём браузеру целевую страницуprint("Переходим на главную TikTok...")page = await browser.get("https://www.tiktok.com/")print("Страница загружена. Если вы её видите в окне браузера, то всё прошло успешно.")print("Ждём 10 секунд перед закрытием...")# Как раз для этого нам и нужна библиотека asyncioawait asyncio.sleep(10)except Exception as err:# На всякий случай обрабатываем исключения. Если возникнет ошибка, мы её выведем в консолиprint(f"Обнаружена ошибка: {err}")finally:# Конец скриптаprint("Тестирование завершено.")if __name__ == "__main__":headlesschrome.loop().run_until_complete(main())
Сохраняем и запускаем. Так как файл хранится в каталоге виртуальной среды, это можно сделать двойным кликом или с помощью контекстного меню (правой кнопкой мышки на файле, выбрать пункт «Открыть с помощью» –> «Python»).
Примерно тут можно начать ощущать себя кулхацкером!
Всё, теперь осталось научить наш TikTok-парсер делать выборку нужного HTML-кода на страницах.
Парсинг профиля TikTok
Для примера возьмём аккаунт самого популярного тиктокера Хаби Лейма. Структура URL для перехода к конкретному профилю выглядит так: https://www.tiktok.com/@khaby.lame.
То есть к основному домену добавляется ник пользователя, перед ником обязательно ставится символ «@».
Даже если вы работаете без авторизации, то вы сможете увидеть:
- Аватарку пользователя.
- Его ник (username) и имя.
- Количество подписок (каналы, на которые подписан пользователь).
- Число его подписчиков (фолловеров).
- Количество лайков.
- Описание профиля (кто-то размещает здесь биографию, кто-то пишет мысли и высказывания, а кто-то проставляет полезные ссылки).
Теперь опустимся до уровня HTML-кода. Откройте свой любимый браузер, перейдите на страницу любого профиля и исследуйте структуру разметки. Для этого наведите курсор на нужный элемент, например, на username, и в контекстном меню (при клике на правой кнопки мыши) выберите пункт «Просмотреть код».
Откроется панель с инструментами разработчика. Фокус в коде будет остановлен как раз на выбранном элементе.
Нужный нам кусок кода выглядит примерно так:
<h1 data-e2e="user-title" class="….">khaby.lame</h1>
Чтобы его быстро найти в общей структуре документа, можно опереться на атрибут «data-e2e="user-title"». Обратите внимание, имя CSS-класса намеренно уникализируется, чтобы усложнить задачу парсинга.
Вы можете пройтись по остальным атрибутам профиля и вычленить нужный HTML-код. Мы не будем занимать ваше время и сразу обозначим актуальные данные списком:
- Атрибут data-e2e="user-subtitle" отвечает за имя пользователя.
- Атрибут data-e2e="user-title" отвечает за ник.
- Атрибут data-e2e="followers-count" отвечает за отображение числа подписчиков.
- Атрибут data-e2e="following-count" – число подписок выбранного профиля.
- Атрибут data-e2e="likes-count" – число лайков.
- Атрибут data-e2e="user-bio" – короткое описание биографии.
Обратите внимание: так как TikTok активно борется с программами парсинга, код может быть изменён. Соответственно, скрипт, который мы приведём ниже, может перестать работать. Чтобы его актуализировать, вам нужно будет самостоятельно найти уникальные атрибуты и подставить их в код TikTok-парсера.
Создайте новый файл проекта, пусть это будет TikTok-profile-parser.py. И наполните его кодом:
# Подключаем нужные библиотеки, наконец используем BeautifulSoupimport asyncioimport nodriver as hdlschromefrom bs4 import BeautifulSoupimport json# Создаём асинхронную функцию и передаём ей в обработку переменную с ником профиляasync def scrape_tiktok_profile(username):try:# Выводим в консоли лог о том, что запустили процесс парсингаprint(f"Запускаем парсинг TikTok профиля: @{username}")# Запускаем экземпляр браузера, опять явно (без скрытия)browser = await hdlschrome.start(headless=False)print("Браузер запущен успешно")# Передаём браузеру URL, который нужно открыть, реальный профиль заменяется на основе переменной usernamepage = await browser.get(f"https://www.tiktok.com/@{username}")print("Страница профиля в TikTok загружена успешно")await asyncio.sleep(30) # Просим браузер выждать 30 секунд, при желании значение можно увеличить или уменьшить. Большой таймаут может быть оправдан для самых медленных подключений.print("Ждём 30 секунд для полной прогрузки контента")# Тут мы передаём результирующий HTML-код в переменную html_content, чтобы потом его распарситьhtml_content = await page.evaluate('document.documentElement.outerHTML')print(f"HTML-контент извлечён: {len(html_content)} символов)")# Передаём HTML-код на обработку в библиотеку анализатора BeautifulSoupsoup = BeautifulSoup(html_content, 'html.parser')print("HTML парсит BeautifulSoup")# Определяем структуру наших данных, в данном случае для описания профиля пользователя TikTokprofile_info = {# Метод select_one позволяет найти только первый элемент с обозначенными атрибутами'username': soup.select_one('h1[data-e2e="user-title"]').text.strip() if soup.select_one('h1[data-e2e="user-title"]') else None,'display_name': soup.select_one('h2[data-e2e="user-subtitle"]').text.strip() if soup.select_one('h2[data-e2e="user-subtitle"]') else None,'follower_count': soup.select_one('strong[data-e2e="followers-count"]').text.strip() if soup.select_one('strong[data-e2e="followers-count"]') else None,'following_count': soup.select_one('strong[data-e2e="following-count"]').text.strip() if soup.select_one('strong[data-e2e="following-count"]') else None,'like_count': soup.select_one('strong[data-e2e="likes-count"]').text.strip() if soup.select_one('strong[data-e2e="likes-count"]') else None,'bio': soup.select_one('h2[data-e2e="user-bio"]').text.strip() if soup.select_one('h2[data-e2e="user-bio"]') else None}print("Информация из профиля извлечена успешно")# Возвращаем данные из профиляreturn profile_info# Обрабатываем исключения и ошибкиexcept Exception as err:print(f"В процессе парсинга возникла ошибка: {str(err)}")return None# Чтобы освободить ресурсы, останавливаем браузерfinally:if 'browser' in locals():browser.stop()print("Закрываем браузер")async def main():# Вот тут вы можете переопределить ник пользователя, данные которого вы хотите пропарситьusername = "khaby.lame"# Создаём асинхронный процесс и передаём функции парсинга переменную с ником пользователяprofile_info = await scrape_tiktok_profile(username)# Если данные непустые, выводим в консоли результат парсингаif profile_info:print("\nИнформация профиля:")# Перебираем массив по ключам, на всякий случай заменяем символы подчёркивания на пробелы, чтобы смотрелось классноfor key, value in profile_info.items():print(f"{key.replace('_', ' ').title()}: {value}")# Сохраняем данные в JSON файлwith open(f"{username}_profile.json", 'w', encoding='utf-8') as f:json.dump(profile_info, f, ensure_ascii=False, indent=4)print(f"Информация из профиля сохранена в файл {username}_profile.json")else:print("Не смогли спарсить информацию из профиля.")if __name__ == "__main__":hdlschrome.loop().run_until_complete(main())Если хотите, чтобы после отработки скрипт не закрывал консоль, нужно запустить свою программу из командной строки:
Сначала смените каталог
cd C:\Users\ВАШ_ПОЛЬЗОВАТЕЛЬ\tiktok-scraper
Теперь запустите сам скрипт
python TikTok-profile-parser.py
Должно получиться примерно так:

Мы специально добавили блок программы для выгрузки данных в JSON-файл. При желании можно организовать выгрузку в табличном формате (CSV) или в базу данных SQLite.
Парсинг страниц видео TikTok
Пример того, как выглядит URL-адрес страницы с видео:
https://www.tiktok.com/@khabylame.62/video/7024119047490964737
В структуре адреса явно угадывается привязка к пользователю, а также указание на идентификатор конкретного видео (вида «/video/<тут_идентификатор>).
На самой странице можно найти:
- Указание автора видео (его ник и отображаемое имя).
- Список хештегов.
- Название музыкальной дорожки/трека.
- Дата публикации.
- Количественные показатели (просмотры, комментарии, число добавления в закладки, репосты и т.п.).
По аналогии с созданием парсера TikTok-профиля, нужно изучить HTML-код страницы видео и найти атрибуты, отвечающие за каждый нужный нам элемент – всё через консоль разработчика браузера.
Не будем вас утомлять скринами. Вот, что нам удалось найти:
- Название музыки – заголовок «h4», с атрибутом data-e2e="browse-music" + смещение вниз по тегам «a» –> «div».
- Дата публикации – элемент «span» с атрибутом data-e2e="browser-nickname", далее смещение вниз до последнего дочернего тега «span».
- Количество лайков – атрибут data-e2e="like-count".
- Количество комментариев – атрибут data-e2e="comment-count"
- Количество репостов – элемент с атрибутом data-e2e="share-count"
- Количество добавления в закладки – data-e2e="undefined-count".
Если добавить эти элементы в код предыдущего скрипта и вместо идентификатора пользователя передать URL видео, то программа спарсит необходимую информацию.
У нас получилось вот так:
# Подключаем нужные библиотеки, используем BeautifulSoupimport asyncioimport nodriver as hdlschromefrom bs4 import BeautifulSoupimport json# Создаём асинхронную функцию и передаём ей в обработку переменную с ID видеоasync def scrape_tiktok_video(video_id):try:# Выводим в консоли лог о том, что запустили процесс парсингаprint(f"Запускаем парсинг TikTok видео: {video_id}")# Запускаем экземпляр браузера, обять явно (без скрытия)browser = await hdlschrome.start(headless=False)print("Браузер запущен успешно")# Передаём браузеру URL, который нужно открыть, идентификатор видео заменяется на основе переменной video_id# Оратите внимнаие, что в URL уже "вшит" ник пользователя!page = await browser.get(f"https://www.tiktok.com/@khabylame.62/video/{video_id}")print("Страница видео в TikTok загружена успешно")await asyncio.sleep(30) # Просим браузер выждать 30 секунд, при желании значение можно увеличить или уменьшитьprint("Ждём 30 секунд для полной прогрузки контента")# Тут мы передаём результирующий HTML-код в переменную html_content, чтобы потом его распарситьhtml_content = await page.evaluate('document.documentElement.outerHTML')print(f"HTML-контент извлечён: {len(html_content)} символов)")# Передаём HTML-код на обработку в библиотеку анализатора BeautifulSoupsoup = BeautifulSoup(html_content, 'html.parser')print("HTML-код парсит BeautifulSoup")# Определяем структуру наших данных, в данном случае для описания профиля пользователя TikTokvideo_info = {# Метод select_one позволяет найти только первый элемент с обозначенными атрибутами'music': soup.select_one('h4[data-e2e="browse-music"] a div').text.strip() if soup.select_one('h4[data-e2e="browse-music"] a div')else None,'likes': soup.select_one('[data-e2e="like-count"]').text.strip() if soup.select_one('[data-e2e="like-count"]')else None,'comments': soup.select_one('[data-e2e="comment-count"]').text.strip() if soup.select_one('[data-e2e="comment-count"]')else None,'shares': soup.select_one('[data-e2e="share-count"]').text.strip() if soup.select_one('[data-e2e="share-count"]')else None,'bookmarks': soup.select_one('[data-e2e="undefined-count"]').text.strip() if soup.select_one('[data-e2e="undefined-count"]')else None,'date': soup.select_one('span[data-e2e="browser-nickname"] span:last-child').text.strip() if soup.select_one('span[data-e2e="browser-nickname"] span:last-child')else None}print("Информация о видео извлечена успешно")# Возвращаем данные о видеоreturn video_info# Обрабатываем исключения и ошибкиexcept Exception as err:print(f"В процессе парсинга возникла ошибка: {str(err)}")return None# Чтобы освободить ресурсы, останавливаем браузерfinally:if 'browser' in locals():browser.stop()print("Закрываем браузер")async def main():# Вот тут вы можете переопределить идентификатор видео, данные которого вы хотите пропарсить, не забудьте заменить в URL ник пользователяvideo_id = "7024119047490964737"# Создаём асинхронный процесс и передаём функции парсинга переменную с ником пользователяvideo_info = await scrape_tiktok_video(video_id)# Если данные непустые, выводим в консоли результат парсингаif video_info:print("\nИнформация о видео:")# Перебираем массив по ключам, на всякий случай заменяем символы подчёркивания на пробелы, чтобы смотрелось классноfor key, value in video_info.items():print(f"{key.replace('_', ' ').title()}: {value}")# Сохраняем данные в JSON файлwith open(f"{video_id}_video.json", 'w', encoding='utf-8') as f:json.dump(video_info, f, ensure_ascii=False, indent=4)print(f"Информация о видео сохранена в файл {video_id}_video.json")else:print("Не смогли спарсить информацию о видео.")if __name__ == "__main__":hdlschrome.loop().run_until_complete(main())
Сохраните код в файл TikTok-video-parser.py и запустите его в консоли.
Вывод лога будет примерно таким:
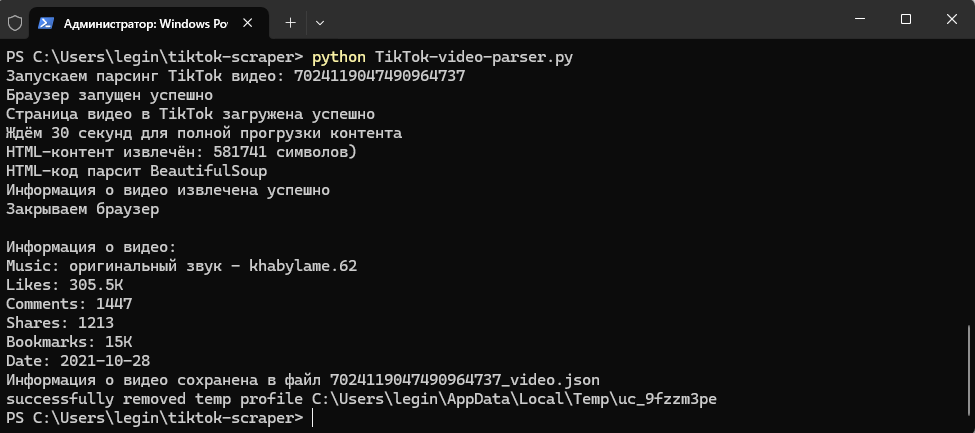
В папке проекта должен появиться JSON-файл с теми же данными.
Парсинг всех видео в профиле TikTok
Повышаем уровень сложности максимально!
Напишем парсер, который будет принимать ник профиля в TikTok и парсить все найденные в нём видео. Более того, все видео будут скачиваться на ПК, а данные по ним будут выгружаться в JSON. Если целевой сайт будет защищаться, например, будет выводить капчу, то парсер будет останавливаться и предлагать пользователю решить эту капчу.
Между запросами поставим случайные задержки, чтобы поведение программы было более “человечным”.
Для скачивания видео нам потребуется библиотека YT_DLP. Ну и в качестве драйвера управления браузером здесь будем использовать Playwright. Материал о сравнении Playwright с Puppeteer.
Поэтому начинаем с установки недостающих библиотек:
pip install playwright yt_dlpОбязательно установите Headless-браузер для Playwright. Это делается командой:playwright install
Непосредственно сам скрипт ниже. Все примечания о его работе читайте в комментариях (после символа #):
# Импортируем библиотекиfrom playwright.async_api import async_playwrightimport asyncio, random, json, logging, time, os, yt_dlp# Настраиваем ведение логовlogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')# Тут флаг включения или отключения необходимости сохранения (загрузки) видеоDOWNLOAD_VIDEOS = False# Определяем задержку между асинхронными запросамиasync def random_sleep(min_seconds, max_seconds):await asyncio.sleep(random.uniform(min_seconds, max_seconds))# Скроллим страницу профиля, тоже с рандомными промежуткамиasync def scroll_page(page):await page.evaluate("""window.scrollBy(0, window.innerHeight);""")await random_sleep(3, 5)# Ждём и обрабатываем показ капчиasync def handle_captcha(page):try:# Если капча не отслеживается, проверьте логику обнаружения диалога - замените div[role="dialog"] на актуальный локаторcaptcha_dialog = page.locator('div[role="dialog"]')# Если капча найдена, то ждём, пока окно не перестанет быть видимым (ведь оно скрывается после решения)is_captcha_present = await captcha_dialog.count() > 0 and await captcha_dialog.is_visible()if is_captcha_present:logging.info("Обнаружена капча. Решите её вручную и закройте другие всплывающие окна на сайте.")# Ждём пока пользователь решит капчуawait page.wait_for_selector('div[role="dialog"]', state='detached', timeout=300000) # Принудительный таймаут на 5 минут, значение задаётся в миллисекундахlogging.info("Капча решена, продолжаем парсинг...")await asyncio.sleep(3) # На всякий случай ещё задержка, но уже после решения капчи, тут в секундах# Обработка ошибокexcept Exception as e:logging.error(f"Ошибка при решении капчи: {str(e)}")async def extract_video_info(page, video_url):# Сначала настройки ожидания видимости контента - параметр domcontentloadedawait page.goto(video_url, wait_until="domcontentloaded")# Случайная задержка, от 2 до 4 секундawait random_sleep(2, 4)# Ждём обработку капчи, если естьawait handle_captcha(page)# Собираем данные о видео (здесь определяется логика парсинга информации о конкретном видео: лайки, комментарии, репосты и т.п.)# Это вкрапление JavaScriptvideo_info = await page.evaluate("""() => {const getTextContent = (selectors) => {for (let selector of selectors) {const elements = document.querySelectorAll(selector);for (let element of elements) {const text = element.textContent.trim();if (text) return text;}}return 'N/A';};const getTags = () => {const tagElements = document.querySelectorAll('a[data-e2e="search-common-link"]');return Array.from(tagElements).map(el => el.textContent.trim());};return {likes: getTextContent(['[data-e2e="like-count"]', '[data-e2e="browse-like-count"]']),comments: getTextContent(['[data-e2e="comment-count"]', '[data-e2e="browse-comment-count"]']),shares: getTextContent(['[data-e2e="share-count"]']),bookmarks: getTextContent(['[data-e2e="undefined-count"]']),musicTitle: getTextContent(['.css-pvx3oa-DivMusicText']),date: getTextContent(['span[data-e2e="browser-nickname"] span:last-child']),tags: getTags()};}""")video_info['url'] = video_url# Ведём логиlogging.info(f"Обработано видео {video_url}: {video_info}")return video_info# Этот блок отвечает за обработку загрузки (сохранения) видео, включается флагом вышеdef download_tiktok_video(video_url, save_path):# Задействуем библиотеку для загрузки и настраиваем качество видеоydl_opts = {'outtmpl': os.path.join(save_path, '%(id)s.%(ext)s'),'format': 'best',}try:with yt_dlp.YoutubeDL(ydl_opts) as ydl:info = ydl.extract_info(video_url, download=True)filename = ydl.prepare_filename(info)# Логируем действияlogging.info(f"Видео успешно загружено: {filename}")return filename# Обработка ошибокexcept Exception as e:logging.error(f"Ошибка загрузки видео: {str(e)}")return None# Блок парсинга TikTok-профиляasync def scrape_tiktok_profile(username, videos=[]):# Запускаем экземпляр headless-браузера через Playwrightasync with async_playwright() as p:# Делаем так, чтобы пользователь видел окно браузера и мог с ним взаимодействоватьbrowser = await p.chromium.launch(headless=False)# Задаём параметры окна и юзер-агентаcontext = await browser.new_context(viewport={'width': 1280, 'height': 720},user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',)page = await context.new_page()# Передаём на загрузку URL профиля, чтобы его изменить, нужно поменять значение переменной username (ищите ниже)url = f"https://www.tiktok.com/@{username}"await page.goto(url, wait_until="domcontentloaded")# Обрабатываем капчуawait handle_captcha(page)# Если массив с видео пока пустойif not videos:videos = []last_video_count = 0no_new_videos_count = 0start_time = time.time()timeout = 300 # На всякий случай таймаут в 5 минут (300 секунд)while True:# Прокручиваем страницу и обрабатываем капчуawait scroll_page(page)await handle_captcha(page)# Ищем блоки с роликами по селектору div с атрибутом data-e2e="user-post-item", если что-то изменилось, актуализируйте на своё значениеvideo_elements = await page.query_selector_all('div[data-e2e="user-post-item"]')# Собираем массив со ссылками на отдельные видеороликиfor element in video_elements:# Вот тут извлекаем сами ссылки (href)video_url = await element.evaluate('(el) => el.querySelector("a").href')if any(video['url'] == video_url for video in videos):continuevideos.append({'url': video_url})# Логируем действияlogging.info(f"Найдено уникальных видео: {len(videos)}")# Счётчик новых видео больше не увеличивается...if len(videos) == last_video_count:no_new_videos_count += 1else:no_new_videos_count = 0last_video_count = len(videos)if no_new_videos_count >= 3 or time.time() - start_time > timeout:# Заканчиваем процесс поискаbreak# Логируем действияlogging.info(f"Всего найдено видео: {len(videos)}")for i, video in enumerate(videos):if 'likes' not in video:video_info = await extract_video_info(page, video['url'])videos[i].update(video_info)logging.info(f"Обрабатываем видео {i+1}/{len(videos)}: {video['url']}")# Если включена опция загрузки, то сохраняем видеоролик локальноif DOWNLOAD_VIDEOS:save_path = os.path.join(os.getcwd(), username)filename = download_tiktok_video(video['url'], save_path)if filename:videos[i]['local_filename'] = filename# Сохраняем процесс каждые 10 секундif (i + 1) % 10 == 0:with open(f"{username}_progress.json", "w") as f:json.dump(videos, f, indent=2)logging.info(f"Процесс сохранён, обработано видео: {i+1}/{len(videos)}...")# Случайная задержка, от 3 до 5 секундawait random_sleep(3, 5)# Закрываем браузерawait browser.close()return videos# Наша главная функцияasync def main():# Вот здесь мы определяем профиль, в котором будем искать видеоusername = "khabylame.62"# Пробуем загрузить процесс с момента, на котором остановилисьtry:with open(f"{username}_progress.json", "r") as f:videos = json.load(f)logging.info(f"Загружаем процесс. {len([v for v in videos if 'likes' in v])}/{len(videos)} видео уже обработаны.")except FileNotFoundError:videos = []if DOWNLOAD_VIDEOS:os.makedirs(username, exist_ok=True)os.chdir(username)videos = await scrape_tiktok_profile(username, videos)logging.info(f"\nВсего пропарсили видео: {len(videos)}")# Сохраняем данные в JSON, файл будет включать имя профиля. Определяем кодировку, чтобы не было проблем с кириллицейwith open(f"{username}_playwright_video_stats.json", "w", encoding='utf-8') as f:json.dump(videos, f, indent=2, ensure_ascii=False)print(f"Данные сохранены в файл {username}_playwright_video_stats.json")logging.info(f"Сохранили данные в файл {username}_playwright_video_stats.json")if __name__ == "__main__":asyncio.run(main())
Сохраните код в файл TikTok-Parser-all-video-in-profile.py и запустите в консоли.
Если хотите, чтобы TikTok-парсер сохранял видео, поменяйте флаг DOWNLOAD_VIDEOS с False на True.
Обязательно следите за выводом в консоли, чтобы вовремя решать капчу. Если вместо капчи показывается любое другое всплывающее окно, например, для продолжения просмотра без входа в аккаунт, просто закройте его и процесс продолжится.
Заключение и рекомендации

Даже сложные динамические сайты, такие как TikTok, можно парсить с минимальным написанием кода. В этом помогают готовые библиотеки и headless-браузеры. В частности, мы привели пример достаточно сложного TikTok-парсера, который принимает на вход ссылку на конкретный профиль, сканирует все видео выбранного пользователя и потом проходит по каждому из них, чтобы собрать ключевые показатели: репосты, лайки, комментарии и прочее. Можно даже скачивать эти видео.
При желании тот же скрипт можно легко переделать для парсинга поисковой выдачи TikTok. Сначала он будет составлять список найденных видео, а затем сканировать страницы конкретных роликов.
Очень быстро можно обнаружить, что TikTok активно защищается от автоматического трафика и показывает большое количество капчи. При массовом парсинге расходы на распознавание капч резко возрастают. Гораздо удобнее и проще заставить работать экземпляры headless-браузера через прокси. Так вы сможете дополнительно ускориться, ведь каждый отдельный поток парсинга будет подключаться через свой прокси.
Найти качественные резидентные, мобильные и серверные прокси с автоматической ротацией можно у Froxy! Для удобного тестирования качества услуг есть недорогой trial-пакет. Froxy – это более 10 млн. IP с таргетингом до уровня города и всегда надежная поддержка.

